Introduction
Maintaining and developing an advanced IT system is a process filled with challenges. A key one is ensuring consistently high-quality services that keep pace with the dynamically changing needs of our system and customers. Goals and priorities set at the beginning evolve as our clients’ businesses develop, continually stimulating the growth of our system’s functionality and the modernization of existing solutions.
Initial priorities
Campstar is a platform that enables the reservation of campers from a variety of providers – you can read about it more in a dedicated Case Study. From a technical point of view it means integration with numerous external APIs.
The start of our collaboration was defined by two key challenges: integration with the leading European suppliers and a rapid market entry.
These business priorities inspired us to create a thoughtful domain model and an advanced search engine, designed with future modifications in mind. In the initial implementation, we used a synchronous mechanism for retrieving data from suppliers via dedicated APIs.
This approach, although relatively simple to implement, provided an adequate level of efficiency due to its low complexity and the limited number of suppliers at the initial stage, resulting in acceptable waiting times for search results.
Simplify base model for APIConnector:
interface ApiConnector {
fun fetchAvailabilities(
city: City,
dropOffCity: City?,
startDateTime: ZonedDateTime,
endDateTime: ZonedDateTime,
searchAreaRadius: Float?
): Collection<OfferDraft>
}
The simplified search model involved synchronously calling each API through the ApiConnector, then returning a collection containing the complete initial results.
Further processing of the results is a topic for another analysis, but we will focus now on the mechanism of their retrieval.
Simplify ApiConnectorRegistry and fetchAvailabilities:
@Component
class ApiConnectorRegistry(
@Autowired val connectors: Collection<ApiConnector>
) {
fun fetchAvailabilities(
city: City,
dropOffCity: City?,
startDateTime: ZonedDateTime,
endDateTime: ZonedDateTime,
supplierBrand: SupplierBrand?,
searchAreaRadius: Float?
): Collection<OfferDraft> {
val results = connectors
.flatMap { connector ->
connector.fetchAvailabilities(city, dropOffCity, startDateTime, endDateTime, searchAreaRadius)
}
return results
}
Growing business
Although this model is intuitive and easy to implement, it generates significant delays. The total data retrieval time is the sum of the times to retrieve from each API.
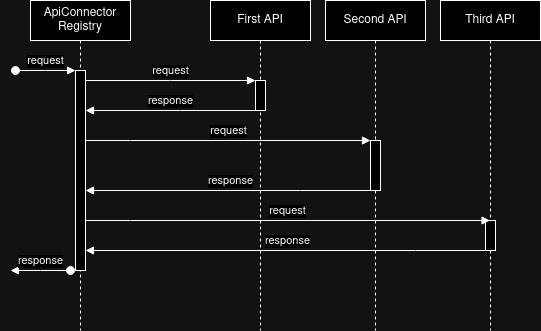
Growing business requirements led us to expand the existing infrastructure and implement new suppliers, which translated into longer waiting times for results.
In response, we conducted an optimization of the search engine, aiming to shorten the loading time. This goal was achieved by asynchronously invoking selected APIs, without needing to modify the code of individual ApiConnector interface implementations.
The key change was the adaptation of the fetchAvailabilities method, which began using the asynchronous CompletableFuture mechanism.
fun fetchAvailabilities(
city: City,
dropOffCity: City?,
startDateTime: ZonedDateTime,
endDateTime: ZonedDateTime,
supplierBrand: SupplierBrand?,
searchAreaRadius: Float?
): Collection<OfferDraft> {
val futures = connectors
.map { connector ->
CompletableFuture.supplyAsync {
connector.fetchAvailabilities(city, dropOffCity, startDateTime, endDateTime, searchAreaRadius)
}.toTypedArray()
CompletableFuture.allOf(*futures).join()
return futures.flatMap { it.get() }
}
Thanks to this solution, asynchronous invocation of the requested APIs allowed for returning results in the time equal to the response from the slowest supplier, without requiring a complicated system refactor.
This facilitated a smooth implementation and deployment of improvements.
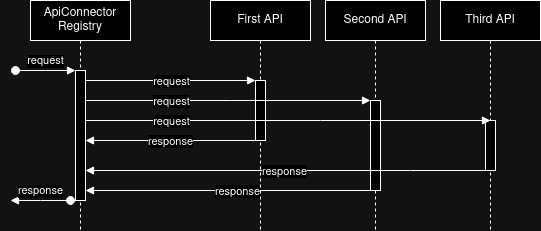
Can we do better?
However, the main drawback of this solution was still having to wait for the response from the slowest supplier. The system’s evolution also resulted in an increase in the number of operations needed to transform the initial offer into the final one (e.g., generating insurance according to specified criteria).
The increasing number of APIs from which data was retrieved motivated us to propose an even faster solution to the customer, which speeds up the generation of SERP pages and makes the processing of offers independent of the slowest supplier.
Modified ApiConnector interface:
interface ApiConnector {
fun fetchAvailabilities(
city: City,
dropOffCity: City?,
startDateTime: ZonedDateTime,
endDateTime: ZonedDateTime,
searchAreaRadius: Float?
): ParallelFlux <OfferDraft>
}
Our solution was the refactor of both the search engine and the individual implementations of the ApiConnector interface using reactive programming and the Reactor.io library.
After the refactor, instead of a traditional collection of results, each implementation of the ApiConnector interface now returns a ParallelFlux. The fetchAvailabilities method in the ApiConnectorRegistry class has been modified by replacing asynchronous processing with the use of reactive streams from the reactor library.
fun fetchAvailabilities(
city: City,
dropOffCity: City?,
startDateTime: ZonedDateTime,
endDateTime: ZonedDateTime,
supplierBrand: SupplierBrand?,
searchAreaRadius: Float?,
): ParallelFlux<OfferDraft> {
return Flux.fromIterable(connectors)
.parallel()
.runOn(Schedulers.boundedElastic())
.flatMap { connector ->
connector.fetchAvailabilities(
city,
dropOffCity,
startDateTime,
endDateTime,
searchAreaRadius
)
}
}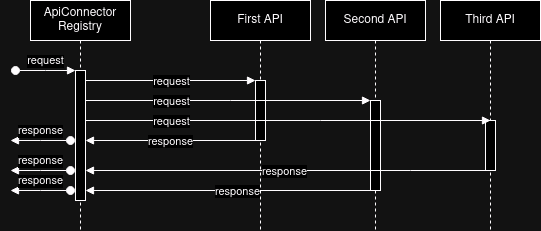
The ApiConnectorRegistry component is now responsible for parallel retrieval of information from various suppliers. Retrieved data in the form of OfferDrafts are forwarded for further processing until the final offer is obtained, which is returned to the end customer as one of the search results.
Thanks to the new approach, the first results are visible to the customer in less than a second.
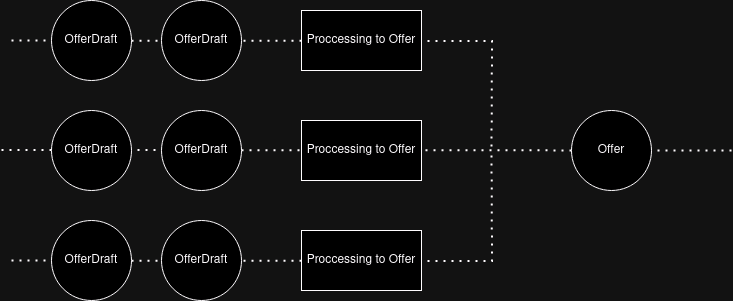
Summary
The evolution of our search engine is certainly not complete and will continue to be adapted to the growing needs of our customers. Throughout this process, which allowed us to accelerate data retrieval and processing by 10x, one of the priorities was the continuity of the system’s operation.


