
Brief
The client approached us with a challenge: to modernize the database layer of a large, long-running system built on outdated technology. The goal was simple yet ambitious — to replace the legacy database engine without disrupting the application logic or affecting end users.
By working together, we:
- Developed a customized migration strategy.
- Selected the most appropriate database technology.
- Created a dedicated data converter.
- Modified the system to run with the new component.
Right now, the system uses NoSQL database, which is faster and easier to maintain. It also doesn’t require any downtime or functional changes.
Client
The client is a healthcare software provider offering innovative products in the DACH region.
Problem
The client asked us to help modernize the system’s database layer. The existing solution ran on an thirty years old object database engine, which had become inefficient both technologically and commercially.
- The technology did not support incremental patches, so each update required shipping a complete database to end clients.
- At this stage of the system’s growth, database files were very large (≈60 GB), making transfers slow, error prone and expensive.
- The vendor supplying the tools for creating and editing the databases raised license prices, making each new deployment commercially unprofitable.
To acquire new customers, the client had to update one of its core systems’ database technology.
Challenge
Replacing the database in such a large system is a complex operation. The client wanted the system to keep doing exactly what it did – just with a more efficient and cost-effective database technology. To solve this problem, we had to answer:
- Which new database technology best fits the client’s requirements and solves the current problems?
- How can we update only the database, without overhauling the system architecture?
- How do we migrate legacy databases to the new technology without losing information?
- How can we execute the update without interrupting service for end users?
Solution
We approach problems like this without preconceived answers, focusing first on the business outcomes and then on the enabling technology choices.
Step 1: Selecting the database technology
The first challenge we faced was selecting a new technology. When analyzing the available options, we kept in mind the reason why the customer came to us:
- The current vendor had raised prices, blocking business growth.
- The object database struggled with incremental data updates. Every change required sending the entire database file, hurting performance and raising operating costs.
Given that keeping the total solution costs down was crucial for the client, we naturally gravitated toward open-source solutions. With so many options available, we knew the new database had to be stable, high-performing, and support a flexible schema along with efficient incremental data writes.
After careful consideration, we ultimately decided to move forward with an open-source document database.
Why? Because it:
- Provides a flexible schema that maps naturally from object models.
- Enables incremental updates (to transmit only changes, not entire database files)
- Delivers strong performance on large, heterogeneous datasets.
- Offers rich querying capabilities, including filtering, aggregations, and full-text search.
- Scales reliably in distributed environments.
In short, the chosen database enables easier updates, faster iteration, lower costs, and supports further system growth.
Step 2: Migrating from object to document database
After choosing the technology, we applied a fail-fast approach to quickly validate both the choice and the feasibility of migrating from an object database to a document store.
Together with the client, we picked a mid-sized database and built a dedicated converter that would:
- read data from the legacy object database,
- Rransform it into a document oriented format, and
- write it to the target document database.
The process ran in stages: the converter retrieved objects and their relationships, then transformed them according to an agreed mapping – embedding some structures directly in documents and representing others as references between collections.
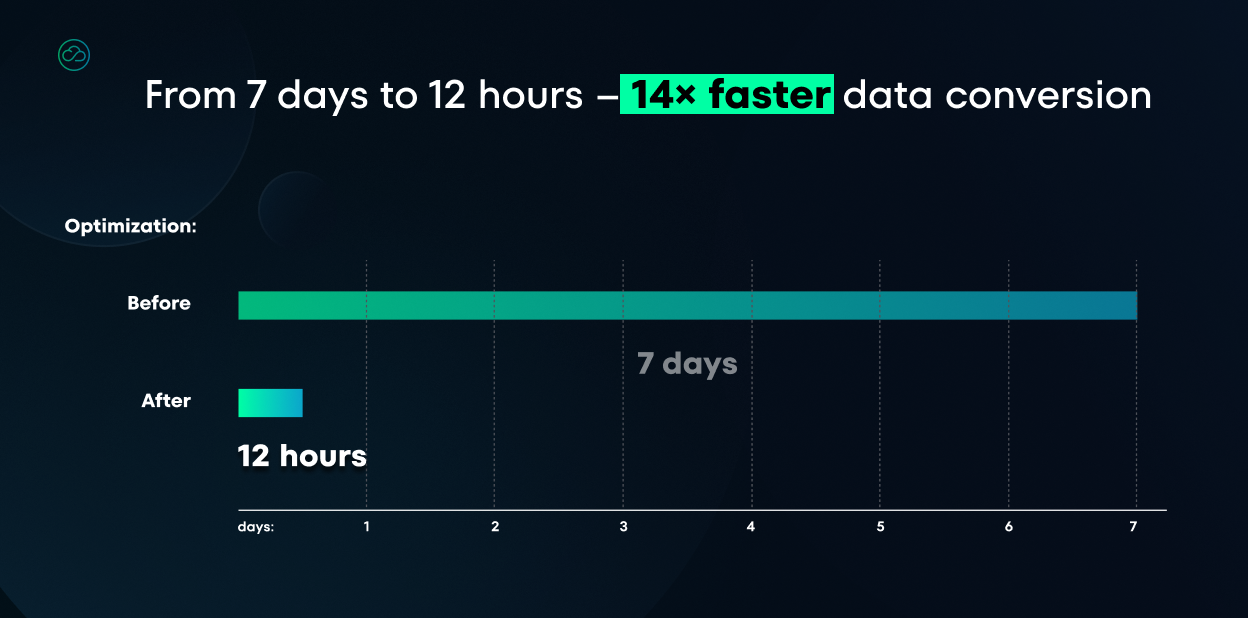
The tool also handled type conversions, generated new identifiers where needed, and split larger structures into smaller units to comply with the NoSQL database engine limits. Due to the database size, the whole operation ran in batches to control memory and track progress.
The test database migration process went smoothly. The data was transferred without a hitch, and there were no problems during type conversion. This confirmed that the selected database technology was the right fit for the system’s requirements.
Success at this stage led to migrating the entire database to the new technology.

Step 3: Swapping the database inside the system
With the new database ready, we adapted the system to use the new database engine.
The good news: the system already had a data-access abstraction layer separating business logic from the concrete database, and it was applied quite rigorously – though there were spots with direct database calls.
The data model was implemented as Java classes that also depended on interfaces and base classes provided by the object-database driver. Removing those dependencies was one of our tasks.
We began by auditing all places where the system talked to the old database. Based on this, we defined clean interfaces at the boundary between application logic and data storage. Next, we implemented those interfaces for the new NoSQL database, using advanced Java mechanisms such as reflection and aspect-oriented programming. This kept changes to existing code relatively small and minimized edits to business logic.
Łukasz Warchał
CTO @NubiSoftThe hardest part was faithfully replicating the old engine’s behavior – especially search and sorting – so that the system using the new database behaved exactly as before.
Automated tests were key: we ran them in parallel on both versions and quickly found and fixed any differences.
We followed the rule “Make It Work. Make It Right. Make It Fast.”
First, we plugged the new database into a few UI views. With feedback from manual and automated tests, we fixed bugs and edge cases. Finally, we optimized performance: using a profiler to find slow spots, then tuning code paths. Knowing real-world read/write patterns, we also added caching.
Once we hit the required performance and functional parity, we moved to deployments. The new app version was immediately used for new customers, while existing installations were migrated in stages: newer ones first (smaller data, lower risk), older long-running ones later (much larger data, requiring extra care). This kept the process smooth and controlled.
Lessons Learned
In this project we built practical know-how for migrating from an object database to a document store while maintaining continuous system operation.
- Using an existing data-access abstraction in a legacy system
We developed an approach that leverages the existing abstraction layer and builds an adapter for the new engine. This limits code changes and minimizes risk of introducing bugs into application logic. - A repeatable migration pipeline (object DB ➝ Document DB)
We built an offline Java converter with clearly defined data-model mapping (embed/reference), type conversions, ID generation, and batch processing of large data volumes. We now have tools and procedures that can be reused for future installations. - Operational playbooks for large on-premise migrations
We have hands-on practice running migrations during maintenance windows, tracking progress, validating outcomes, and ready-made rollback scenarios – focused on continuity of service and minimal downtime.
If you’re facing a similar challenge, we can show you how to replace a database in a live production system without affecting application logic or interrupting operations.
People who read this article also read:


